Équipe HULTECH : "HUman Language TECHnology" : thème "Rhétorique et Génie linguistique"
Laboratoire GREYC
Université de Caen
F14032 Caen Cedex
| Site : | Campus II |
| Bâtiment : | S3 |
| Étage : | 3 |
| Bureau : | S3 391 |
Tél. : +33 (0)2 31 56 73 36
Fax : +33 (0)2 31 56 73 30
 Jacques.Vergne@unicaen.fr
Jacques.Vergne@unicaen.fr
Fonction : Professeur
page modifiée le 24 avril 2008
 NB : les textes non publiés sont mis à disposition sous un
contrat Creative Commons.
NB : les textes non publiés sont mis à disposition sous un
contrat Creative Commons.
![]() Abstracts in English and English version of some slides
Abstracts in English and English version of some slides
[Conférences invitées à
l'Université Stendhal Grenoble 3 - novembre 2004]
![]() [Local function words discovery in raw corpora
of unknown languages, without any resource submitted to SIGIR'2004]
[Local function words discovery in raw corpora
of unknown languages, without any resource submitted to SIGIR'2004]
![]() [Article et présentation aux
Journées Francophones de la Toile 2003 (JFT 2003) du 2 juillet
2003]
[Article et présentation aux
Journées Francophones de la Toile 2003 (JFT 2003) du 2 juillet
2003]
![]() [Article et présentation
à l'atelier "TALN et multilinguisme" de TALN 2003 du 14 juin 2003]
[Article et présentation
à l'atelier "TALN et multilinguisme" de TALN 2003 du 14 juin 2003]
![]() [Article et présentation
à TALN 2002 du 24 juin 2002]
[Article et présentation
à TALN 2002 du 24 juin 2002]
[Séminaire I3 du GREYC du 9 octobre 2001]
![]() [Conférence invitée
à TALN 2001 du 3 juillet 2001]
[Conférence invitée
à TALN 2001 du 3 juillet 2001]
[Exposé à la journée "Prédication" du CRISCO du 26 janvier 2001]
![]() [Exposé au séminaire
TALANA du 4 décembre 2000]
[Exposé au séminaire
TALANA du 4 décembre 2000]
![]() [Tutoriel
au Coling 2000 : Trends in Robust Parsing]
[Tutoriel
au Coling 2000 : Trends in Robust Parsing]
![]() [
A linear algorithm for chunk linking] submitted to Coling'2000
[
A linear algorithm for chunk linking] submitted to Coling'2000
![]() [
Between dependency tree and linear order, two transforming processes] submitted to Coling'98's DG workshop
[
Between dependency tree and linear order, two transforming processes] submitted to Coling'98's DG workshop
[ Une hypothèse sur l'ordre linéaire: l'arbre de dépendance et sa linéarisation, optimisée sous des contraintes topologiques, métriques et mémorielles] soumis en 1996 à la revue Linguisticae Investigationes
![]() [
A short term memory based algorithm for linking segments]
submitted to Coling'96
[
A short term memory based algorithm for linking segments]
submitted to Coling'96
[ Les cadres théoriques des TAL syntaxiques: quelle adéquation linguistique et algorithmique ?] TALN'95
![]() [
Some syntactic properties of natural languages, applied to parsing of linear complexity in time]
submitted to Coling'94
[
Some syntactic properties of natural languages, applied to parsing of linear complexity in time]
submitted to Coling'94
![]() [
A non-recursive sentence segmentation, applied to parsing of linear complexity in time]
NEMLAP'94
[
A non-recursive sentence segmentation, applied to parsing of linear complexity in time]
NEMLAP'94
![]() [
Syntactic properties of natural languages and application to automatic parsing]
SEPLN'93
[
Syntactic properties of natural languages and application to automatic parsing]
SEPLN'93
![]() [
Syntax as clipping blocks: structures, algorithms and rules ]
SEPLN'92
[
Syntax as clipping blocks: structures, algorithms and rules ]
SEPLN'92
![]() [
Syntax as clipping blocks: structures, algorithms and rules ]
submitted to Coling'92
[
Syntax as clipping blocks: structures, algorithms and rules ]
submitted to Coling'92
![]() [
A parser without a dictionary as a tool for research into French syntax ]
Coling'90
[
A parser without a dictionary as a tool for research into French syntax ]
Coling'90
[Publications] [Axes de recherche] [Groupe Syntaxe] [Étudiants en thèse]
[Analyseur syntaxique 98] [Analyseur syntaxique du GREYC]
[Habilitation à diriger des recherches]
[GRACE] [Projet
Synthèse Vocale] [Projet industriel DATOPS]
Article à CIDE 8 - mai 2005
Une méthode indépendante des langues
pour indexer les documents de l'internet par extraction de termes de
structure contrôlée
Résumé - Abstract
Nous présentons dans cet article une méthode d'indexation
automatique de documents de l'internet, fondée sur l'extraction de
termes de structure contrôlée, et qui ne nécessite aucun
traitement linguistique, ni stop-list, ni connaissance de la(les) langue(s)
du document. Cette méthode s'appuie sur la récurrence de suites
de mots, et sur le contrôle de la structure de ces suites. Ce contrôle
de structure est basé sur un étiquetage du texte à indexer
avec un jeu de deux étiquettes : mots informatifs ou non informatifs.
Les mots informatifs sont définis comme étant plus longs et
moins fréquents que leurs voisins. On exploite ainsi des propriétés
très générales des langues, découvertes par Zipf
et par Saussure.
Mots-clés, Key-words : indexation automatique,
termes de structure contrôlée, méthode d’indexation indépendante
des langues. automatic indexing, structure controlled terms, language independent
indexing method.
![]() In this paper, we present an automatic indexing method
of web documents, based on structure controlled terms extraction, and which
does not require any linguistic processing, neither stop-list, nor knowing
the document language(s). This method relies on the words sequences recurrence,
and on the structure control of these sequences. This structure control is
based on tagging the text to index with a two label tagset : informative words
or not. Informative words are defined longer and less frequent than their
neighbours. Very general linguistic properties, discovered by Zipf and by
Saussure are thus exploited.
In this paper, we present an automatic indexing method
of web documents, based on structure controlled terms extraction, and which
does not require any linguistic processing, neither stop-list, nor knowing
the document language(s). This method relies on the words sequences recurrence,
and on the structure control of these sequences. This structure control is
based on tagging the text to index with a two label tagset : informative words
or not. Informative words are defined longer and less frequent than their
neighbours. Very general linguistic properties, discovered by Zipf and by
Saussure are thus exploited.
Téléchargez l'article (.pdf
288 Ko)
Vergne Jacques. Une méthode indépendante des langues pour indexer les documents de l'internet par extraction de termes de structure contrôlée. Actes de CIDE 8, 2005, 155-168.
Conférences invitées à l'Université Stendhal Grenoble 3 - novembre 2004
Un exemple de traitement "alingue" endogène
:
extraction de candidats termes dans des corpus bruts de langues
non identifiées
par étiquetage mot vide - mot plein
"Ceci n'est pas une pipe"
dissocier un phénomène de sa représentation
--->
multiplicité des modèles
Article soumis à SIGIR'2004 - juillet 2004
Local function words discovery in raw corpora
of unknown languages, without any resource
Abstract
![]() Our present research is in the field of exploring NLP methods which use no other resource than the text to analyse itself. This drives us to analysis methods which use very general linguistic properties, as for instance differences of length and frequencies of words. To illustrate our approach, we present in this paper a local computation method to discover function words from raw corpora. This method can be used to extract term candidates or to index raw texts in unidentified alphabetic natural languages.
Our present research is in the field of exploring NLP methods which use no other resource than the text to analyse itself. This drives us to analysis methods which use very general linguistic properties, as for instance differences of length and frequencies of words. To illustrate our approach, we present in this paper a local computation method to discover function words from raw corpora. This method can be used to extract term candidates or to index raw texts in unidentified alphabetic natural languages.
Key-words : multilingual NLP, natural language learning,
grammar induction, function words discovery
Téléchargez l'article (.pdf 244 Ko)
Article et poster aux JADT 2004 - mars 2004
Découverte locale des mots vides dans des
corpus bruts de langues inconnues, sans aucune ressource
Résumé - Abstract
Nous nous plaçons dans une perspective de traitements linguistiques
sans autre ressource que le texte à analyser. Ceci nous conduit
à des méthodes d’analyse exploitant des propriétés
très générales des langues, comme par exemple les
différences de longueur et de fréquence des mots. Pour illustrer
notre démarche, nous présentons dans cet article une méthode
de découverte des mots vides par un calcul local. Cette méthode
peut s’appliquer à l’extraction de candidats termes ou à l’indexation
de textes bruts de langues alphabétiques non identifiées.
Mots-clés, Key-words : traitements multilingues,
découverte des mots vides, multilingual NLP, natural language learning,
grammar induction, function words discovery
![]() Our present research is in the field of exploring NLP
methods using no other resource than the text to analyse itself. This
drives us to analysis methods which use very general linguistic properties,
as for instance differences of length and frequencies of words. To illustrate
our approach, we present in this paper a method of local computation for
discovering function words from raw corpora. This method can be used for
extracting term candidates or indexing raw texts of unidentified alphabetic
natural languages.
Our present research is in the field of exploring NLP
methods using no other resource than the text to analyse itself. This
drives us to analysis methods which use very general linguistic properties,
as for instance differences of length and frequencies of words. To illustrate
our approach, we present in this paper a method of local computation for
discovering function words from raw corpora. This method can be used for
extracting term candidates or indexing raw texts of unidentified alphabetic
natural languages.
Téléchargez l'article (.pdf184
Ko)
Vergne Jacques. Découverte locale des mots vides dans des corpus bruts de langues inconnues, sans aucune ressource. Actes des JADT 2004, volume 2, 2004, 1158-1164.
Article et présentation aux JFT 2003 du 2 juillet 2003
Un système de calcul des thèmes
de l'actualité à partir des sites de presse de l'internet
Résumé - Abstract
Dans cet article, nous présentons un système de constitution
de revue de presse à partir des sites de presse présents
sur l'internet . Il s'agit de répondre à des questions
telles que : "de qui, de quoi est-il question aujourd'hui dans la presse
de tel espace géographique ou linguistique ?". L'utilisateur,
qu'il soit un journaliste qui prépare sa revue de presse, ou simplement
une personne intéressée par l'actualité, définit
en entrée l'espace de recherche qui l'intéresse. Ce système
inverse la problématique des moteurs de recherche : au lieu de
rechercher des documents à partir de mots-clés qui représentent
des thèmes, il s'agit de produire en sortie les thèmes
principaux de l'actualité, et de donner accès aux articles
concernés par ces thèmes. Les thèmes d'actualité
sont capturés en relevant les termes récurrents dans les
"textes" d'hyperliens des "Unes" des sites de presse. Le système
calcule un graphe de termes dans lequel les nœuds sont les termes et les
arcs sont les relations entre termes, relations définies par la
co-occurrence de deux termes dans un "texte" d'hyperlien. L'interface exploite
ce graphe en permettant à l'utilisateur de naviguer parmi les termes
et d'avoir accès aux articles contenant ces termes.
Mots-clés : hypertextes, web, internet, documents électroniques,
web mining, recherche d'informations, veille stratégique, fouille
de textes.
![]() In this paper, we present a system for building a news
review, from news sites on the web. We want to be able to answer questions
as : "who, what are papers speaking about today in the news of a given
geographic or linguistic search space". The user, a journalist preparing
his news review, or somebody interested in news, defines as input the
search space he is interested in. This system reverses the issues of search
engines : in spite of searching documents from key-words which represents
topics, we want to produce as output the main topics of the news, and to
give access to related papers. News topics are captured while computing
recurrent terms in hyperlinks texts of front-pages of news sites. The
system computes a graph in which nodes are terms and arcs are links between
terms; a link is defined as a co-occurrence of two terms in a same link
text. The interface is based on this graph as the user can browse through
the terms and have access to papers containing these terms.
In this paper, we present a system for building a news
review, from news sites on the web. We want to be able to answer questions
as : "who, what are papers speaking about today in the news of a given
geographic or linguistic search space". The user, a journalist preparing
his news review, or somebody interested in news, defines as input the
search space he is interested in. This system reverses the issues of search
engines : in spite of searching documents from key-words which represents
topics, we want to produce as output the main topics of the news, and to
give access to related papers. News topics are captured while computing
recurrent terms in hyperlinks texts of front-pages of news sites. The
system computes a graph in which nodes are terms and arcs are links between
terms; a link is defined as a co-occurrence of two terms in a same link
text. The interface is based on this graph as the user can browse through
the terms and have access to papers containing these terms.
Key-words : hypertexts, web, internet, electronic documents,
web mining, information retrieval, strategic watching, text mining.
Téléchargez l'article (.pdf
256 Ko), la présentation (.ppt
544 Ko)
Une démonstration est accessible sur : https://lucasn01.users.greyc.fr/JacquesVergne/demoRevueDePresse/
Vergne Jacques. Un système de calcul des thèmes de l'actualité à partir des sites de presse de l'internet. Actes des JFT 2003, tome 2, 2003, 215-224.
Article et présentation à l'atelier "TALN et multilinguisme" de TALN 2003 du 14 juin 2003
Un outil d'extraction terminologique endogène
et multilingue
A tool for endogenous and multilingual
terminological extraction
Résumé - Abstract
Dans cet article, nous présentons un outil d'extraction terminologique
"endogène" à partir d'un corpus multilingue. Cet outil
est qualifié d'endogène car, sans autre ressource que le
corpus dont il doit extraire les termes, il calcule les mots vides à
partir de ce corpus pour centrer les termes candidats sur des mots pleins.
Il est placé dans le cadre d'un système de constitution
automatique de revue de presse à partir de sites de presse présents
sur l'internet . Il s'agit de répondre à des questions
telles que : "de qui, de quoi est-il question aujourd'hui dans la presse
de tel espace géographique ou linguistique ?". Le corpus est constitué
des textes des hyperliens des "Unes" des sites de presse de langues inconnues
a priori. Il est renouvelé quotidiennement, et sa taille est
d'environ 100 Ko (débalisé). La méthode est fondée
sur l'analyse distributionnelle, et utilise des différences entre
mots contigus : les différences de longueur et d'effectif.
![]() In this paper, we present an "endogenous" terminology
mining tool, from a multilingual corpus. This tool is described as
endogenous because, without any other resource than the corpus from
which it has to extract terms, it computes function words from this
corpus to focus candidate terms on content terms. It is used inside
an automatic news review system from news web sites. The system is able
to answer questions as : "who, what are newspapers speaking about today
in a given geographic or linguistic search space?". The corpus is made
of hyperlinks texts of news web site front-pages in unknown languages.
It is daily downloaded, and its size is about 100 Kbytes (untagged). The
method is based on distributional analysis, and uses differences between
contiguous words : differences of length and of frequency.
In this paper, we present an "endogenous" terminology
mining tool, from a multilingual corpus. This tool is described as
endogenous because, without any other resource than the corpus from
which it has to extract terms, it computes function words from this
corpus to focus candidate terms on content terms. It is used inside
an automatic news review system from news web sites. The system is able
to answer questions as : "who, what are newspapers speaking about today
in a given geographic or linguistic search space?". The corpus is made
of hyperlinks texts of news web site front-pages in unknown languages.
It is daily downloaded, and its size is about 100 Kbytes (untagged). The
method is based on distributional analysis, and uses differences between
contiguous words : differences of length and of frequency.
Mots Clés – Keywords
extraction terminologique, endogène, multilingue, internet,
fouille de texte.
terminology mining, endogenous, multilingual, internet, web
mining, text mining.
Téléchargez l'article (.pdf
96 Ko), la présentation (.ppt
490 Ko,
![]() .ppt 540 Ko, )
.ppt 540 Ko, )
Une démonstration est accessible sur : https://lucasn01.users.greyc.fr/JacquesVergne/demoRevueDePresse/
Vergne Jacques. Un outil d'extraction terminologique endogène et multilingue. Actes de TALN 2003, tome 2, 2003, 139-148.
Article et présentation à TALN 2002 du 24 juin 2002
Une méthode pour l'analyse descendante
et calculatoire
de corpus multilingues :
application au calcul des relations
sujet-verbe
application : computing subject-verb links
Résumé - Abstract
Nous présentons une méthode d'analyse descendante et calculatoire. La démarche d'analyse est descendante du document à la proposition, en passant par la phrase. Le prototype présenté prend en entrée des documents en anglais, français, italien, espagnol, ou allemand. Il segmente les phrases en propositions, et calcule les relations sujet-verbe dans les propositions. Il est calculatoire, car il exécute un petit nombre d'opérations sur les données. Il utilise très peu de ressources (environ 200 mots et locutions par langue), et le traitement de la phrase fait environ 60 Ko de Perl, ressources lexicales comprises. La méthode présentée se situe dans le cadre d'une recherche plus générale du Groupe Syntaxe et Ingénierie Multilingue du GREYC sur l'exploration de solutions minimales et multilingues, ajustées à une tâche donnée, exploitant peu de propriétés linguistiques profondes, la généricité allant de pair avec l'efficacité.
![]() We present a method for top-down and calculatory parsing.
The prototype we present is top-down from the document to the clause,
through the sentence. Its inputs are documents in English, French,
Italian, Spanish, or German. It tokenises sentences into clauses, and
computes subject-verb links inside clauses. It is calculatory, as it
executes few operations on data. It uses very few resources (about 200
words or locutions per natural language), and the sentence processing
size is about 60 Kb Perl, including lexical resources. This method takes
place in the frame of more general researches of the "Groupe Syntaxe et
Ingénierie Multilingue du GREYC" into exploring minimal and multilingual
solutions, close fitted to a given task, exploiting few deep linguistic
properties, presuming that genericity implies efficiency.
We present a method for top-down and calculatory parsing.
The prototype we present is top-down from the document to the clause,
through the sentence. Its inputs are documents in English, French,
Italian, Spanish, or German. It tokenises sentences into clauses, and
computes subject-verb links inside clauses. It is calculatory, as it
executes few operations on data. It uses very few resources (about 200
words or locutions per natural language), and the sentence processing
size is about 60 Kb Perl, including lexical resources. This method takes
place in the frame of more general researches of the "Groupe Syntaxe et
Ingénierie Multilingue du GREYC" into exploring minimal and multilingual
solutions, close fitted to a given task, exploiting few deep linguistic
properties, presuming that genericity implies efficiency.
Téléchargez l'article (.pdf
120 Ko), la présentation (.ppt 210
Ko,
![]() .ppt 260 Ko, )
.ppt 260 Ko, )
Vergne Jacques (2002). Une méthode pour l'analyse descendante et calculatoire de corpus multilingues : application au calcul des relations sujet-verbe, Actes de TALN 2002, 63-74.
Séminaire I3 du GREYC du 9 octobre 2001
Une expérience d’analyse syntaxique calculatoire minimale
Objectifs du Groupe Syntaxe :
- recherche de solutions minimales : pour une tâche donnée, minimiser les moyens utilisés
- tout petits programmes
- algorithmes très simples
- solutions calculatoires (pas d’exploration combinatoire)
- bases linguistiques minimales :
. utilisation de très peu de propriétés, seulement celles qui servent aux calculs
. très peu de ressources (lexicales, morphologiques, typographiques)
à titres expérimental et pédagogique, choix d'une tâche classique, limitée et (apparemment) simple : détecter et relier sujets et verbes, avec le plus petit programme possible
Téléchargez la présentation
: (.ppt.zip
70 Ko) (.ppt
330Ko)
Conférence invitée à TALN 2001 du 3 juillet 2001
Analyse syntaxique automatique de langues : du "combinatoire" au "calculatoire"
Parsing natural languages : from "combinatorial" to "deterministic" parsing
Point de départ :
- notre analyseur 98 :
-
- 1ère place à l'action d'évaluation
GRACE (1995-1998)
- quelles sont les caractéristiques de cet analyseur ? c'est un analyseur calculatoire
- Grammaires et Ressources pour les Analyseurs de Corpus et leur évaluation
- 22 participants de France, Suisse, Allemagne, Québec, USA : labos, entreprises (dont AT&T, IBM, Xerox, France-Télécom)
- jeu de 311 étiquettes
- décision = 100% (= tokens avec étiquette unique / total des tokens)
- précision = 94,5% (= tokens ayant la même étiquette que l'humain / tokens avec étiquette unique)
- nous placer dans l'évolution historique des analyseurs
- comprendre les principes de l'analyse calculatoire
- pouvoir construire des analyseurs calculatoires
Téléchargez l'article (.pdf
56 Ko), la présentation : (.ppt.zip
120 Ko) (.ppt 340Ko,
![]() .ppt 390 Ko)
.ppt 390 Ko)
Vergne Jacques (2001). Analyse syntaxique automatique de langues : du combinatoire au calculatoire (communication invitée), Actes de TALN 2001, 15-29.
Exposé à la journée "Prédication" du CRISCO du 26 janvier 2001
Comment discriminer automatiquement les formes verbales des formes nominales ?
Comment modéliser la proposition ? Et comment utiliser ce modèle en analyse automatique ?
téléchargez la présentation : (.ppt.zip 130 Ko) (.pdf.zip 1,2 Mo)
Exposé au séminaire TALANA du 4 décembre 2000
Ordre linéaire des constituants : vers une généralisation
Linear order of constituents : towards a generalisation
Comment poser plus généralement la question de
l'ordre des mots dans une phrase en telle langueen allant vers une étude de
l'ordre des X dans les Y (indépendamment de la langue)en généralisant : - dans la dimension des constituants
- dans la dimension des languesQuelques liens avec la prosodie et avec l'analyse syntaxique
téléchargez la présentation : (.ppt.zip 108 Ko) (.pdf.zip 208 Ko, .ppt 550 Ko)
Axes de recherche
Étude et modélisation de la syntaxe des langues à l'aide de l'ordinateur
Analyse syntaxique automatique non combinatoire
Mes recherches se développent simultanément sur les deux axes conjoints de la linguistique informatique et de l'informatique linguistique :
- linguistique informatique : Étude et modélisation de la syntaxe des langues à l'aide de l'ordinateur
-
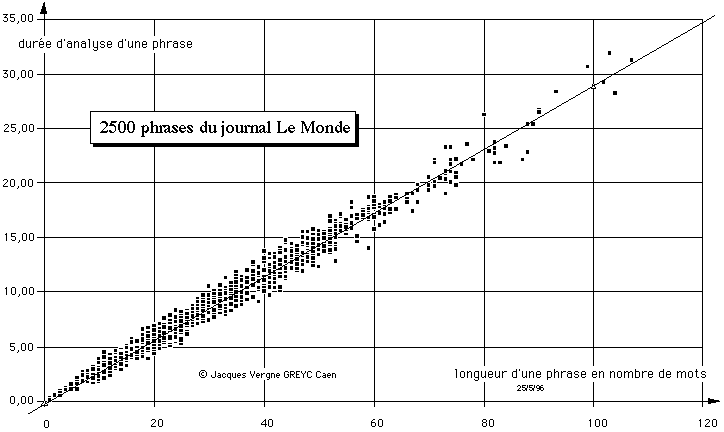
Jacques Vergne. 1998. Entre arbre de dépendance et ordre linéaire,
les deux processus de transformation : linéarisation, puis
reconstruction de l'arbre. Cahiers de
Grammaire, n°23 (Cahiers
de Grammaire), Toulouse, France, (paru le 12 avril 99).
(.pdf 196 Ko)
- informatique linguistique : Analyse syntaxique automatique non combinatoire
{kind=link}
-
Jacques Vergne et Emmanuel
Giguet. 1998. Regards Théoriques
sur le "Tagging". In actes de la cinquième
conférence Le Traitement Automatique des Langues Naturelles
(TALN
1998), Paris, France, 10-12 juin.
(Postscript, PDF, RTF, HTML)
- Emmanuel Giguet : analyse syntaxique multilingue (thèse soutenue le 22 décembre 1998)
- Hervé Déjean : découverte de structures syntaxiques à partir de corpus (thèse soutenue le 18 décembre 1998)
- Gérald Vannier : prosodie et syntaxe, dans le cadre du Projet Synthèse Vocale (thèse soutenue le 29 juin 1999)
- Thomas Lebarbé : Explorations Linguistiques en Intelligence Artificielle Distribuée (thèse soutenue le 23 mai 2002)
- Frédérick Houben : Découverte automatique des structures formelles des langues à partir de corpus brut
- Luquet Pierre-Sylvain : Méthode pour la classification d'échantillons de signal de parole
- Grégory Smits : Évaluation dynamique multicritères des résultats d’une chaîne d’analyse linguistique
Analyseur syntaxique 98 : visualiseur développé en Java par Emmanuel Giguet
Habilitation à Diriger des Recherches, soutenue le 29 septembre 1999, devant le jury :
-
Patrice Enjalbert, Violaine Prince,
Jean Véronis, Daniel Kayser, Bernard Victorri, Pierre Zweigenbaum
Analyse syntaxique automatique non combinatoire
Synthèse et Résultats
Participation à l'action d'évaluation comparative des étiqueteurs du français : GRACE
-
Grammaires et Ressources
pour les Analyseurs de Corpus et leur Evaluation
publication du graphique des premiers résultats au 6 novembre 1998
{kind=link}
greyc : décision = 1,00 et précision = 0,945 (petitecroixXen haut à droite)
Le système du GREYC est le plus proche
du point : décision = 1 et précision = 1
-
Jacques Vergne
et Emmanuel Giguet. 1998. Regards
Théoriques sur le "Tagging". In actes de la cinquième conférence Le
Traitement Automatique des Langues Naturelles (TALN 1998),
Paris, France, 10-12 juin.
(Postscript, PDF, RTF, HTML)
Projet Synthèse Vocale (financement FEDER) avec les partenaires :
- CRISCO (laboratoire de l'Université de Caen) avec Anne Lacheret et Michel Morel
- ELECTREL (PME caennaise) avec Hélène Grimaud
- Club MicroSon (association d'utilisateurs) avec Jean Poitevin et Alain Rousseau
{kind=link}
démonstration (fichiers wav)
démonstration en ligne, avec accès à tous les paramètres
-
Gérald
Vannier, Anne Lacheret-Dujour, Jacques Vergne. 1999. Pauses
location and duration calculated with syntactic dependencies and textual
considerations for t.t.s. system. ICPhS 1999,
San Francisco, USA, aôut 99.
(PDF 80 Ko)
Projet industriel DATOPS (financement MENRT)
(mot-clé : text mining)
Membre de l'ATALa, Association
pour les Traitements Atutomatiques des Langues
Membre de l'ACL, Association for Computational Linguistics