
Analyseur syntaxique du GREYC
novembre 1999
Jacques Vergne, Emmanuel Giguet, Nadine Lucas, Grégoire Cousin
La version de novembre 1999 de l'analyseur du GREYC est une refonte complète de l'analyseur de Jacques Vergne, par le Groupe Syntaxe du GREYC, dans la foulée du projet Linguix, projet de transfert de technologie réalisé dans le cadre de la collaboration industrielle avec Datops (financement MENRT).
L'analyse syntaxique porte sur des zones textuelles d'un document dont la langue a été diagnostiquée, ce qui permet de choisir correctement les ressources pour l'anglais ou le français, ou de ne pas déclencher l'analyse syntaxique si le document est dans une autre langue.
Conception globale
L'analyseur syntaxique du GREYC se situe dans la lignée des taggers et des chunkers, outils linguistiques capables de fonctionner sur internet, grâce à leur capacité à traiter en flux. Il apporte une résolution calculatoire à l'analyse syntaxique, c'est-à-dire non combinatoire : au lieu d'attendre des structures syntaxiques explicitées dans une grammaire formelle, il exécute un processus de calcul sur le flux textuel, processus explicité dans des règles déclaratives, processus qui produit les structures en sortie au lieu de s'en servir en entrée.
L'ouverture de la langue est ainsi prise en compte explicitement : une langue n'est pas caractérisable exhaustivement, contrairement à un langage de programmation. Ceci entraîne que les ressources lexicales sont partielles, et même minimales, et qu'il n'y a pas de grammaire formelle (pas d'inventaire exhaustif des structures syntaxiques attendues), ni de test de grammaticalité de chaque phrase.
Le processus de calcul consiste à passer des règles "conditions => actions" une fois sur chaque unité : mots graphiques, tokens, syntagmes, propositions, phrases, (paragraphes, ... , textes entiers). Les conditions portent sur les attributs d'unités et sur les relations entre unités, les actions affectent des valeurs aux attributs, établissent des relations, et génèrent les unités du niveau supérieur. Le traitement est en flux, c'est-à-dire à débit constant, sans découper a priori une unité à traiter dans sa totalité telle que la phrase. Un élément du flux est traité complètement, une fois pour toutes, en couche unique, avant de passer à l'élément suivant.
Le tagging (étiquetage grammatical des mots d'un texte) et le chunking (segmentation des textes en syntagmes nominaux ou verbaux non récursifs) sont déjà classiquement résolus de manière calculatoire et ont aussi une complexité pratique linéaire. Mais l'analyseur du GREYC est capable de calculer les mises en relation sans grammaire formelle, et en temps linéaire, grâce à l'algorithme conçu par Jacques Vergne et modélisé par Emmanuel Giguet sous forme d'un calcul sur un graphe.
Algorithme de mise en relation de 2 unités linguistiques
L'algorithme de mise en relation de 2 unités en 2 temps par l'intermédiaire d'une unité virtuelle est présenté ci-dessous sous la forme d'un calcul sur un graphe dont les nÏuds sont des unités et les arcs des relations entre unités :
- le flux d'unités (chunks, ou propositions) est traité dans leur ordre d'arrivée (dans le schéma, l'unité i , puis l'unité j ).
- au temps 1, au moment où l'unité i arrive, elle est reliée à l'unité virtuelle, qu'on peut invoquer dans les règles à tout moment; par exemple, si l'unité i est un chunk nominal, on peut ainsi la placer en attente de son chunk verbal (relation de type sujet-verbe) :
- au temps 2, à l'arrivée de l'unité j (par exemple un chunk verbal), une condition d'une règle vérifie s'il existe une unité reliée à l'unité virtuelle par la relation d'un type spécifié (sujet-verbe) :

ensuite une action de cette règle relie les 2 unités (type sujet-verbe) :

- enfin, la relation entre l'unité i et l'unité virtuelle est supprimée, ce qui revient à exprimer dans notre exemple que ce sujet a trouvé son verbe et n'en attend plus d'autre :

Ce processus est implémenté dans 2 règles : une pour traiter l'unité i , la deuxième pour traiter l'unité j . Il est généralisé pour toute unité, des paragraphes par exemple dans l'analyse logique.
Démarche multilingue
Il s'agit de s'abstraire progressivement de la langue des documents. La démarche est multilingue sur les plans suivants :
La langue d'un texte est une particularité certes frappante, mais classiquement surévaluée, et on peut s'abstraire de la langue du document dans l'analyse automatique par la démarche suivante :
L'analyse syntaxique comme enchaînement de tâches par le moteur générique
L'analyse syntaxique est un cas particulier de fonctionnement du moteur générique :
Le flux de sortie est un flux XML, où donc les unités linguistiques en sortie sont hiérarchiquement imbriquées, et où un niveau est composé d'un type d'unité ou d'unités de niveau inférieur. Chaque unité comporte une liste d'attributs - valeurs. Les relations entre unités sont codées par des balises de relations placées en fin de document, et comportant les ID des unités source et cible et le type de la relation.
L'analyse syntaxique consiste en un enchaînement de tâches; chaque tâche a son propre paquet de règles pour une langue donnée, prend en entrée des unités d'un niveau N (ou inférieur), produit en sortie des unités du niveau N+1, modifie les valeurs d'attributs des unités de niveau N+1 (ou inférieur), et relie des unités du niveau N (ou inférieur) à l'intérieur des unités de niveau N+1.
À partir du mot graphique (atome physique), la stratégie globale est montante dans la hiérarchie des unités linguistiques construites par l'application des règles sur les unités : tokens, chunks, propositions, phrases. On cherche à obtenir une montée rapide dans la hiérarchie, en s'attachant prioritairement au calcul des valeurs des attributs des unités élevées, à l'aide de certains attributs d'unités inférieures : on veut ainsi caractériser au plus vite les "gros grains" en s'attardant le moins possible aux "petits grains". Cette stratégie permet un traitement plus rapide.
Complexité de l'analyseur : complexité linéaire en temps => débit constant
Au sujet de la complexité de l'analyseur, il est important de bien préciser la différence conceptuelle entre la complexité en temps et le temps de traitement d'un volume donné.
Les analyseurs traditionnels (qui énumèrent une combinatoire) ont une complexité théorique exponentielle et une complexité pratique en O(n3); ceci signifie que la fonction : temps de traitement d'une phrase = f(nombre de mots de la phrase) est de la forme :
complexité théorique : temps de traitement d'une phrase = k . e nombre de mots de la phrase
complexité pratique : temps de traitement d'une phrase = k . (nombre de mots de la phrase)3
ce qui donne un graphe ayant l'allure suivante :

L'évolution réalisée dans l'analyseur du GREYC (comme dans les analyseurs précédents de Jacques Vergne) est de passer d'une complexité exponentielle (ou en n3) à une complexité linéaire, c'est-à-dire de remplacer dans le graphe ci-dessus la courbe exponentielle ou cubique par une droite d'équation :
temps de traitement d'une phrase = k . (nombre de mots de la phrase)1 (complexité pratique)
d'où : k = temps de traitement d'une phrase / nombre de mots de la phrase, en secondes / mot, ou bien : débit = 1/ k = nombre de mots de la phrase / temps de traitement d'une phrase, en mots / s.
Cela signifie que le temps de traitement d'une phrase est proportionnel à son nombre de mots, ou que le nombre de mots traité par unité de temps est constant. Si on appelle "débit" le nombre de mots traités par unité de temps, alors on peut dire que le débit (en mots/s) est constant.
Le mot étant une unité de longueur variable, il nous semble préférable de choisir l'octet / seconde comme unité de débit.
Cette évolution de la complexité est un progrès radical dû à la conception des algorithmes, et on ne peut pallier une mauvaise complexité par une amélioration matérielle telle que l'augmentation de la fréquence des processeurs ou par leur multiplication (traitement en parallèle).
Nous avons choisi le terme "analyse en flux" pour exprimer que l'analyse est faite à débit constant.
L'analyse en flux a comme caractéristique de pouvoir prévoir la valeur du débit : il suffit de le mesurer avec une machine définie, un environnement logiciel défini, des ressources définies, pour un corpus assez volumineux (quelques Mo), alors le débit pour tout corpus analogue (en particulier vis-à-vis de la proportion texte / balises HTML) sera prévisible et stable. Cette caractéristique est fondamentale en situation industrielle, et l'analyseur du GREYC n'a pas, à notre connaissance, de concurrent (l'analyse linguistique en flux de milliers de dépêches est un défi que l'analyseur du GREYC est capable de relever).
Une fois la complexité linéaire réalisée, quand le débit est constant, alors un deuxième défi est à relever : celui obtenir un débit constant plus élevé, ce qui revient à diminuer la pente de la droite (pente = 1/ débit) :
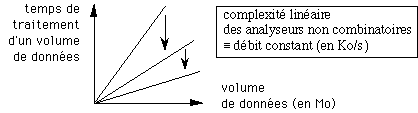
Une telle augmentation de débit peut s'obtenir par une amélioration matérielle telle que l'augmentation de la fréquence des processeurs ou par leur multiplication.
À moyen terme, nous pensons obtenir une augmentation de débit par un travail sur l'exploitation fine des propriétés linguistiques qui permettra un allégement des ressources (car le débit est aussi proportionnel au volume des ressources) et un travail sur la manière dont le moteur interprète les ressources.
Nous présentons ci-dessous le nuage de points (un point représente un document) dans le repère : temps d'analyse du document en ms en ordonnée, taille totale du document en octets en abscisse, sur 900 documents analysés en flux.
N.B. : les points très éloignés de la droite de régression linéaire représentent des documents traités plus vite ou plus lentement que le faisait prévoir le débit moyen (= 1/pente = 2,3 Ko / seconde) car ces documents ont une proportion de balises HTML très supérieure ou très inférieure à la moyenne.
